Lifecycle
Reatom is a heavy inspired by actor model, which important quality is that each component of the system is isolated from the others. This isolation is achieved by the fact that each component has its own state and its own lifecycle. This is the same for an atoms. We have API that allows you to create a system of components that are independent of each other and can be used in different modules with minimum setup. This is the main advantage of Reatom over other state management libraries.
For example, you could create some data resource, which depends of a backend service and will connect to the service only when the data atom used. This is a very common case for a frontend application. In Reatom you could do it with lifecycle hooks.
import { atom, action } from '@reatom/core'
import { onConnect } from '@reatom/hooks'
export const listAtom = atom([], 'listAtom')
export const fetchList = action(
(ctx) =>
ctx.schedule(async () => {
const list = await api.getList()
listAtom(ctx, list)
}),
'fetchList',
)
onConnect(listAtom, (ctx) => fetchList(ctx))What happens here? We want to fetch the list only when a user comes to the relative page and the UI subscribes to listAtom. It is work same as useEffect(fetchList, []) in React.js. As an atoms represents a shared state the connection status is “one for many” listeners, which means an onConnect hook triggers only for a first subscriber and not calling for a new listeners. It is super useful coz you could use listAtom in many components to reduce props drilling, but request the side effect only once. If an user leaves the page and all subscriptions gone the atom marks as unconnected, an onConnect hook will called again only when a new subscription occurs.
The important knowledge about Reatom atoms is that they are lazy. It means that they will be connected only when they will be used. This usage is possible only by ctx.subscribe, but the magic of underhood Reatom graph is that ctx.spy apply connections too! So, if you have a main data atom, compute some others atoms from it and use them in some components, the main atom will be connected when some component will be mounted.
const filteredListAtom = atom((ctx) => {
const list = ctx.spy(fetchList)
return list.filter(somePredicate)
})
ctx.subscribe(filteredListAtom, sideEffect)The code above will trigger listAtom connection and fetchList call as expected.
Notice that the links between computed atoms have only a one direction -
filteredListAtomis a dependency oflistAtom, in other wordsfilteredListAtomis a dependent fromlistAtom.listAtomdoesn’t know aboutfilteredListAtom. If you haveonConnect(filteredListAtom, cb)and onlylistAtomhave a subscription the callback will not be called.
When you use an adapter package, like npm-react, under the hood it will use ctx.subscribe to listen the fresh state of the atom. So, if you connect an atom with useAtom, the atom will be connected when the component will be mounted.
const [filteredList] = useAtom(filteredListAtom)Now, you have lazy computations and lazy effects!
This pattern allow you to stay control of data neednes in view layer or any other consumer module, but do it implicitly, and explicitly for data models. You don’t need extra start actions or something like that. It is a more clean and scalable way to design your code, with better ability to reuse a components.
A lot of cool examples you could find in async package docs.
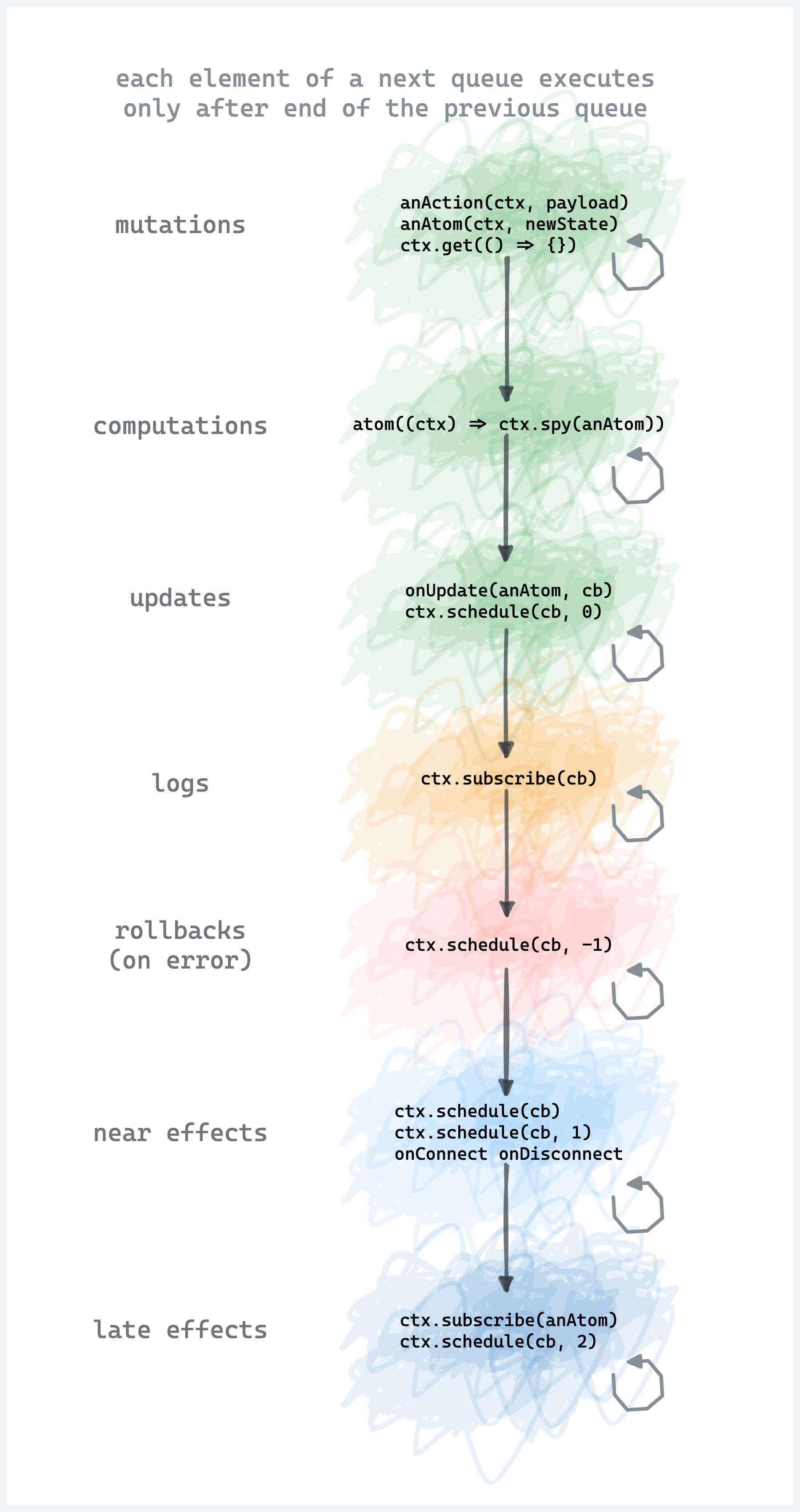
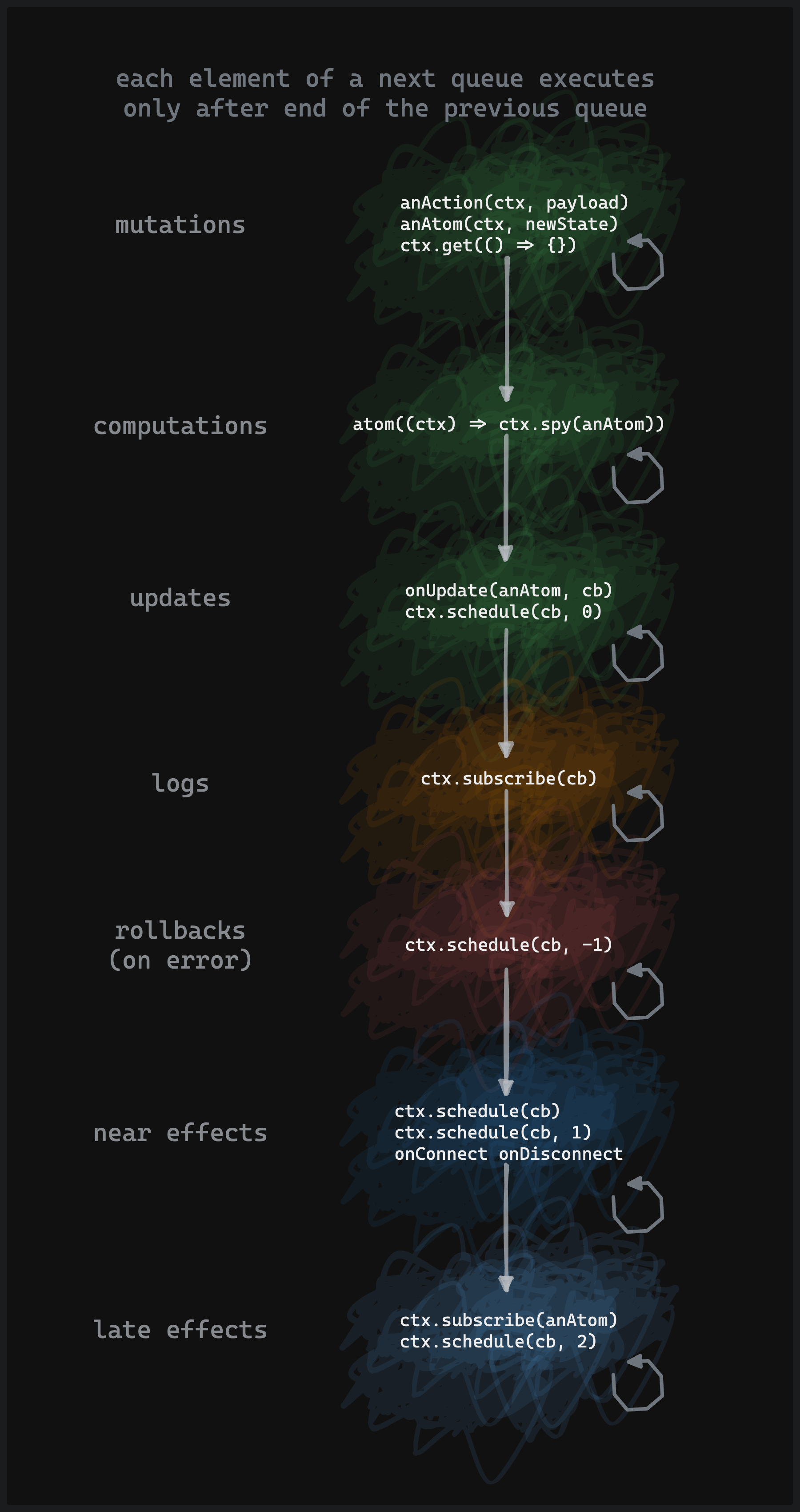
Lifecycle scheme
Here is a scheme of the execution order of the build-in queues.
Check ctx.schedule docs for more details about the ability to use the queues.